 zerone
zerone2023 年 9 月份
大部分题目来自力扣以及掘金社区,这个月定的目标是每天一道吧,闲的时候一天 4 道,不论简单还是困难。
函数防抖
题目:请你编写一个函数,接收参数为另一个函数和一个以毫秒为单位的时间 t ,并返回该函数的 函数防抖 后的结果。函数防抖 方法是一个函数,它的执行被延迟了 t 毫秒,如果在这个时间窗口内再次调用它,它的执行将被取消。你编写的防抖函数也应该接收传递的参数。例如,假设 t = 50ms ,函数分别在 30ms 、 60ms 和 100ms 时调用。前两个函数调用将被取消,第三个函数调用将在 150ms 执行。如果改为 t = 35ms ,则第一个调用将被取消,第二个调用将在 95ms 执行,第三个调用将在 135ms 执行。
示例 (1) :
输入:
t = 50
calls = [
{"t": 50, inputs: [1]},
{"t": 75, inputs: [2]}
]
输出:[{"t": 125, inputs: [2]}]
解释:
let start = Date.now();
function log(...inputs) {
console.log([Date.now() - start, inputs ])
}
const dlog = debounce(log, 50);
setTimeout(() = dlog(1), 50);
setTimeout(() = dlog(2), 75);
第一次调用被第二次调用取消,因为第二次调用发生在 100ms 之前
第二次调用延迟 50ms,在 125ms 执行。输入为 (2)。
示例 (2) :
输入:
t = 20
calls = [
{"t": 50, inputs: [1]},
{"t": 100, inputs: [2]}
]
输出:[{"t": 70, inputs: [1]}, {"t": 120, inputs: [2]}]
解释:
第一次调用延迟到 70ms。输入为 (1)。
第二次调用延迟到 120ms。输入为 (2)。
示例 (3) :
输入:
t = 150
calls = [
{"t": 50, inputs: [1, 2]},
{"t": 300, inputs: [3, 4]},
{"t": 300, inputs: [5, 6]}
]
输出:[{"t": 200, inputs: [1,2]}, {"t": 450, inputs: [5, 6]}]
解释:
第一次调用延迟了 150ms,运行时间为 200ms。输入为 (1, 2)。
第二次调用被第三次调用取消
第三次调用延迟了 150ms,运行时间为 450ms。输入为 (5, 6)。示例 (1) :
输入:
t = 50
calls = [
{"t": 50, inputs: [1]},
{"t": 75, inputs: [2]}
]
输出:[{"t": 125, inputs: [2]}]
解释:
let start = Date.now();
function log(...inputs) {
console.log([Date.now() - start, inputs ])
}
const dlog = debounce(log, 50);
setTimeout(() = dlog(1), 50);
setTimeout(() = dlog(2), 75);
第一次调用被第二次调用取消,因为第二次调用发生在 100ms 之前
第二次调用延迟 50ms,在 125ms 执行。输入为 (2)。
示例 (2) :
输入:
t = 20
calls = [
{"t": 50, inputs: [1]},
{"t": 100, inputs: [2]}
]
输出:[{"t": 70, inputs: [1]}, {"t": 120, inputs: [2]}]
解释:
第一次调用延迟到 70ms。输入为 (1)。
第二次调用延迟到 120ms。输入为 (2)。
示例 (3) :
输入:
t = 150
calls = [
{"t": 50, inputs: [1, 2]},
{"t": 300, inputs: [3, 4]},
{"t": 300, inputs: [5, 6]}
]
输出:[{"t": 200, inputs: [1,2]}, {"t": 450, inputs: [5, 6]}]
解释:
第一次调用延迟了 150ms,运行时间为 200ms。输入为 (1, 2)。
第二次调用被第三次调用取消
第三次调用延迟了 150ms,运行时间为 450ms。输入为 (5, 6)。解法
这题考核是基础的防抖思想以及获取函数参数(args)的基本功,从示例中可以看出debounce方法接受两个参数,分别是时间和方法。那么解法就非常明显了
const debounce = (fn, t) = {
let time = null;
return function (...args) {
if (time) clearInterval(time);
time = setInterval(() = {
fn(...args);
clearInterval(time);
}, t);
};
};const debounce = (fn, t) = {
let time = null;
return function (...args) {
if (time) clearInterval(time);
time = setInterval(() = {
fn(...args);
clearInterval(time);
}, t);
};
};数组分组
题目:请你编写一段可应用于所有数组的代码,使任何数组调用 array. groupBy(fn) 方法时,它返回对该数组 分组后 的结果。数组 分组 是一个对象,其中的每个键都是 fn(arr[i]) 的输出的一个数组,该数组中含有原数组中具有该键的所有项。提供的回调函数 fn 将接受数组中的项并返回一个字符串类型的键。每个值列表的顺序应该与元素在数组中出现的顺序相同。任何顺序的键都是可以接受的。请在不使用 lodash 的 _.groupBy 函数的前提下解决这个问题。
示例(1):
array = [
{"id":"1"},
{"id":"1"},
{"id":"2"}
],
fn = function (item) {
return item.id;
}
输出:
{
"1": [{"id": "1"}, {"id": "1"}],
"2": [{"id": "2"}]
}
解释:
输出来自函数 array.groupBy(fn)。
分组选择方法是从数组中的每个项中获取 "id" 。
有两个 "id" 为 1 的对象。所以将这两个对象都放在第一个数组中。
有一个 "id" 为 2 的对象。所以该对象被放到第二个数组中。
示例(2):
输入:
array = [
[1, 2, 3],
[1, 3, 5],
[1, 5, 9]
]
fn = function (list) {
return String(list[0]);
}
输出:
{
"1": [[1, 2, 3], [1, 3, 5], [1, 5, 9]]
}
解释:
数组可以是任何类型的。在本例中,分组选择方法是将键定义为数组中的第一个元素。
所有数组的第一个元素都是 1,所以它们被组合在一起。
{
"1": [[1, 2, 3], [1, 3, 5], [1, 5, 9]]
}
示例(3):
输出:
array = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
fn = function (n) {
return String(n 5);
}
输入:
{
"true": [6, 7, 8, 9, 10],
"false": [1, 2, 3, 4, 5]
}
解释:
分组选择方法是根据每个数字是否大于 5 来分割数组。示例(1):
array = [
{"id":"1"},
{"id":"1"},
{"id":"2"}
],
fn = function (item) {
return item.id;
}
输出:
{
"1": [{"id": "1"}, {"id": "1"}],
"2": [{"id": "2"}]
}
解释:
输出来自函数 array.groupBy(fn)。
分组选择方法是从数组中的每个项中获取 "id" 。
有两个 "id" 为 1 的对象。所以将这两个对象都放在第一个数组中。
有一个 "id" 为 2 的对象。所以该对象被放到第二个数组中。
示例(2):
输入:
array = [
[1, 2, 3],
[1, 3, 5],
[1, 5, 9]
]
fn = function (list) {
return String(list[0]);
}
输出:
{
"1": [[1, 2, 3], [1, 3, 5], [1, 5, 9]]
}
解释:
数组可以是任何类型的。在本例中,分组选择方法是将键定义为数组中的第一个元素。
所有数组的第一个元素都是 1,所以它们被组合在一起。
{
"1": [[1, 2, 3], [1, 3, 5], [1, 5, 9]]
}
示例(3):
输出:
array = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
fn = function (n) {
return String(n 5);
}
输入:
{
"true": [6, 7, 8, 9, 10],
"false": [1, 2, 3, 4, 5]
}
解释:
分组选择方法是根据每个数字是否大于 5 来分割数组。解法
功能不难,核心在于能否 get 到把参数传进去先判断而已
Array.prototype.groupBy = function (fn) {
let result = {};
this.forEach((item) = {
let key = fn(item);
if (!result[key]) {
result[key] = [item];
} else {
result[key].push(item);
}
});
return result;
};Array.prototype.groupBy = function (fn) {
let result = {};
this.forEach((item) = {
let key = fn(item);
if (!result[key]) {
result[key] = [item];
} else {
result[key].push(item);
}
});
return result;
};过滤数组中的元素 (手搓 Array.filter)
给定一个整数数组 arr 和一个过滤函数 fn,并返回一个过滤后的数组 filteredArr 。fn 函数接受一个或两个参数:
- arr[i] - arr 中的数字
- i - arr[i] 的索引
filteredArr 应该只包含使表达式 fn(arr[i], i) 的值为 真值 的 arr 中的元素。真值 是指 Boolean(value) 返回参数为 true 的值。请在不使用内置的 Array.filter 方法的情况下解决该问题。讲人话就是手搓 Array.filter
const filter = (arr, fn) => {
let result = [];
if (Array.isArray(arr)) {
arr.forEach((item, index) => {
if (fn(item, index)) result.push(item);
});
}
return result;
};const filter = (arr, fn) => {
let result = [];
if (Array.isArray(arr)) {
arr.forEach((item, index) => {
if (fn(item, index)) result.push(item);
});
}
return result;
};转换数组中的每个元素
编写一个函数,这个函数接收一个整数数组 arr 和一个映射函数 fn ,通过该映射函数返回一个新的数组。返回数组的创建语句应为 returnedArray[i] = fn(arr[i], i) 。你在不使用内置方法 Array.map 的前提下解决这个问题。
示例 1:
输入:arr = [1,2,3], fn = function plusone(n) { return n + 1; }
输出:[2,3,4]
解释:
const newArray = map(arr, plusone); // [2,3,4]
此映射函数返回值是将数组中每个元素的值加 1。
示例 2:
输入:arr = [1,2,3], fn = function plusI(n, i) { return n + i; }
输出:[1,3,5]
解释:此映射函数返回值根据输入数组索引增加每个值。
示例 3:
输入:arr = [10,20,30], fn = function constant() { return 42; }
输出:[42,42,42]
解释:此映射函数返回值恒为 42。示例 1:
输入:arr = [1,2,3], fn = function plusone(n) { return n + 1; }
输出:[2,3,4]
解释:
const newArray = map(arr, plusone); // [2,3,4]
此映射函数返回值是将数组中每个元素的值加 1。
示例 2:
输入:arr = [1,2,3], fn = function plusI(n, i) { return n + i; }
输出:[1,3,5]
解释:此映射函数返回值根据输入数组索引增加每个值。
示例 3:
输入:arr = [10,20,30], fn = function constant() { return 42; }
输出:[42,42,42]
解释:此映射函数返回值恒为 42。解法
过于简单,不做说明
cosnt map = (arr, fn) => {
let result = []
arr.forEach((item,index) => {
result.push(fn(item,index))
})
return result
};cosnt map = (arr, fn) => {
let result = []
arr.forEach((item,index) => {
result.push(fn(item,index))
})
return result
};有时间限制的缓存
编写一个类,它允许获取和设置键-值对,并且每个键都有一个 过期时间 。该类有三个公共方法:set(key, value, duration) :接收参数为整型键 key 、整型值 value 和以毫秒为单位的持续时间 duration 。一旦 duration 到期后这个键就无法访问。如果相同的未过期键已经存在,该方法将返回 true ,否则返回 false 。如果该键已经存在,则它的值和持续时间都应该被覆盖。get(key) :如果存在一个未过期的键,它应该返回这个键相关的值。否则返回 -1 。count() :返回未过期键的总数。 要求:
示例 1:
输入:
["TimeLimitedCache", "set", "get", "count", "get"]
[[], [1, 42, 100], [1], [], [1]]
[0, 0, 50, 50, 150]
输出: [null, false, 42, 1, -1]
解释:
在 t=0 时,缓存被构造。
在 t=0 时,添加一个键值对 (1: 42) ,过期时间为 100ms 。因为该值不存在,因此返回false。
在 t=50 时,请求 key=1 并返回值 42。
在 t=50 时,调用 count() ,缓存中有一个未过期的键。
在 t=100 时,key=1 到期。
在 t=150 时,调用 get(1) ,返回 -1,因为缓存是空的。
示例 2:
输入:
["TimeLimitedCache", "set", "set", "get", "get", "get", "count"]
[[], [1, 42, 50], [1, 50, 100], [1], [1], [1], []]
[0, 0, 40, 50, 120, 200, 250]
输出: [null, false, true, 50, 50, -1]
解释:
在 t=0 时,缓存被构造。
在 t=0 时,添加一个键值对 (1: 42) ,过期时间为 50ms。因为该值不存在,因此返回false。
当 t=40 时,添加一个键值对 (1: 50) ,过期时间为 100ms。因为一个未过期的键已经存在,返回 true 并覆盖这个键的旧值。
在 t=50 时,调用 get(1) ,返回 50。
在 t=120 时,调用 get(1) ,返回 50。
在 t=140 时,key=1 过期。
在 t=200 时,调用 get(1) ,但缓存为空,因此返回 -1。
在 t=250 时,count() 返回0 ,因为缓存是空的,没有未过期的键。
提示:
0 <= key <= 109
0 <= value <= 109
0 <= duration <= 1000
方法调用总数不会超过 100示例 1:
输入:
["TimeLimitedCache", "set", "get", "count", "get"]
[[], [1, 42, 100], [1], [], [1]]
[0, 0, 50, 50, 150]
输出: [null, false, 42, 1, -1]
解释:
在 t=0 时,缓存被构造。
在 t=0 时,添加一个键值对 (1: 42) ,过期时间为 100ms 。因为该值不存在,因此返回false。
在 t=50 时,请求 key=1 并返回值 42。
在 t=50 时,调用 count() ,缓存中有一个未过期的键。
在 t=100 时,key=1 到期。
在 t=150 时,调用 get(1) ,返回 -1,因为缓存是空的。
示例 2:
输入:
["TimeLimitedCache", "set", "set", "get", "get", "get", "count"]
[[], [1, 42, 50], [1, 50, 100], [1], [1], [1], []]
[0, 0, 40, 50, 120, 200, 250]
输出: [null, false, true, 50, 50, -1]
解释:
在 t=0 时,缓存被构造。
在 t=0 时,添加一个键值对 (1: 42) ,过期时间为 50ms。因为该值不存在,因此返回false。
当 t=40 时,添加一个键值对 (1: 50) ,过期时间为 100ms。因为一个未过期的键已经存在,返回 true 并覆盖这个键的旧值。
在 t=50 时,调用 get(1) ,返回 50。
在 t=120 时,调用 get(1) ,返回 50。
在 t=140 时,key=1 过期。
在 t=200 时,调用 get(1) ,但缓存为空,因此返回 -1。
在 t=250 时,count() 返回0 ,因为缓存是空的,没有未过期的键。
提示:
0 <= key <= 109
0 <= value <= 109
0 <= duration <= 1000
方法调用总数不会超过 100解法
class TimeLimitedCache {
dataMap = new Map();
timeMap = new Map();
set(key, value, duration) {
let now = new Date().getTime();
if (this.timeMap.get(key) !== undefined) {
this.dataMap.set(key, value);
this.timeMap.set(key, now + duration);
if (now > this.timeMap.get(key)) return false;
else return true;
}
this.dataMap.set(key, value);
this.timeMap.set(key, now + duration);
return false;
}
get(key) {
let now = new Date().getTime();
if (!this.timeMap.has(key)) return -1;
if (now > this.timeMap.get(key)) return -1;
else return this.dataMap.get(key);
}
count() {
let now = new Date().getTime();
let counter = 0;
this.timeMap.forEach((value) => {
if (now < value) counter++;
});
return counter;
}
}class TimeLimitedCache {
dataMap = new Map();
timeMap = new Map();
set(key, value, duration) {
let now = new Date().getTime();
if (this.timeMap.get(key) !== undefined) {
this.dataMap.set(key, value);
this.timeMap.set(key, now + duration);
if (now > this.timeMap.get(key)) return false;
else return true;
}
this.dataMap.set(key, value);
this.timeMap.set(key, now + duration);
return false;
}
get(key) {
let now = new Date().getTime();
if (!this.timeMap.has(key)) return -1;
if (now > this.timeMap.get(key)) return -1;
else return this.dataMap.get(key);
}
count() {
let now = new Date().getTime();
let counter = 0;
this.timeMap.forEach((value) => {
if (now < value) counter++;
});
return counter;
}
}哈希 map 缓存
请你编写一个函数,它接收另一个函数作为输入,并返回该函数的 记忆化 后的结果。记忆函数 是一个对于相同的输入永远不会被调用两次的函数。相反,它将返回一个缓存值。
解法
function memoize(fn) {
let list = {};
return function (...args) {
if (list.hasOwnProperty(args)) {
return list[args];
}
list[args] = fn(...args);
return list[args];
};
}function memoize(fn) {
let list = {};
return function (...args) {
if (list.hasOwnProperty(args)) {
return list[args];
}
list[args] = fn(...args);
return list[args];
};
}蜗牛排序
请你编写一段代码为所有数组实现 snail(rowsCount,colsCount) 方法,该方法将 1D 数组转换为以蜗牛排序的模式的 2D 数组。无效的输入值应该输出一个空数组。当 rowsCount * colsCount !==nums.length 时。这个输入被认为是无效的。
蜗牛排序从左上角的单元格开始,从当前数组的第一个值开始。然后,它从上到下遍历第一列,接着移动到右边的下一列,并从下到上遍历它。将这种模式持续下去,每列交替变换遍历方向,直到覆盖整个数组。例如,当给定输入数组 [19, 10, 3, 7, 9, 8, 5, 2, 1, 17, 16, 14, 12, 18, 6, 13, 11, 20, 4, 15] ,当 rowsCount = 5 且 colsCount = 4 时,需要输出矩阵如下图所示。注意,矩阵沿箭头方向对应于原数组中数字的顺序;
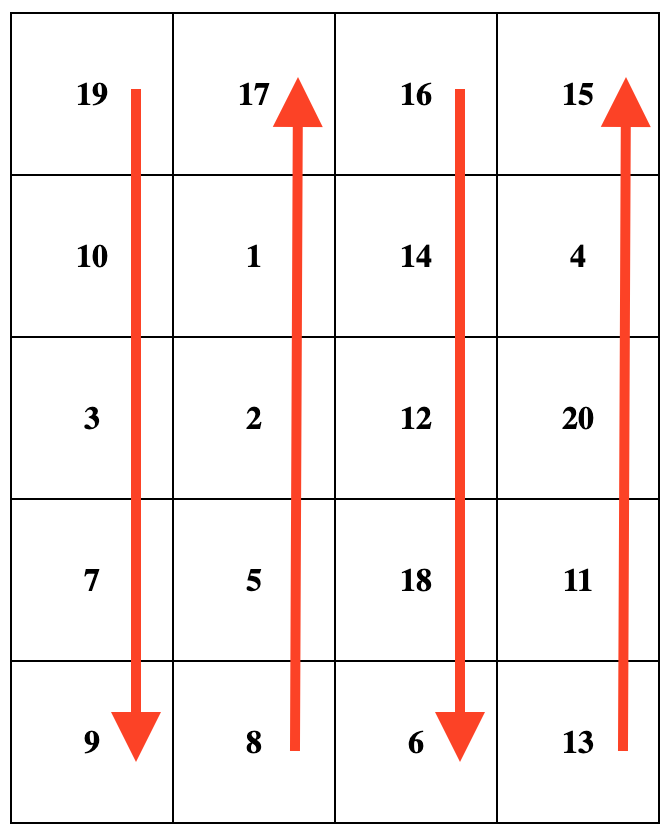
输入:
nums = [19, 10, 3, 7, 9, 8, 5, 2, 1, 17, 16, 14, 12, 18, 6, 13, 11, 20, 4, 15]
rowsCount = 5
colsCount = 4
输出:
[
[19,17,16,15],
[10,1,14,4],
[3,2,12,20],
[7,5,18,11],
[9,8,6,13]
]
示例 2:
输入:
nums = [1,2,3,4]
rowsCount = 1
colsCount = 4
输出:[[1, 2, 3, 4]]
示例 3:
输入:
nums = [1,3]
rowsCount = 2
colsCount = 2
输出:[]
Explanation: 2 * 2 = 4, 且原数组 [1,3] 的长度为 2; 所以,输入是无效的。输入:
nums = [19, 10, 3, 7, 9, 8, 5, 2, 1, 17, 16, 14, 12, 18, 6, 13, 11, 20, 4, 15]
rowsCount = 5
colsCount = 4
输出:
[
[19,17,16,15],
[10,1,14,4],
[3,2,12,20],
[7,5,18,11],
[9,8,6,13]
]
示例 2:
输入:
nums = [1,2,3,4]
rowsCount = 1
colsCount = 4
输出:[[1, 2, 3, 4]]
示例 3:
输入:
nums = [1,3]
rowsCount = 2
colsCount = 2
输出:[]
Explanation: 2 * 2 = 4, 且原数组 [1,3] 的长度为 2; 所以,输入是无效的。解法
这道题讲实话,一开始我是没有写出来而且写的很乱,各种 for 嵌套 for,后面实在顶不住了(毕竟上班时间练习的),去观察了一位大神写的,简直是醍醐灌顶,确实我为什么一定要从数组中隔着 X 去获取数据组装成示例一样呢? 为什么不就从这个一维数组中,按顺序循环去拼接想要的结果,ok 文字会比较生涩,直接从贴代码:
Array.prototype.snail = (rowsCount, colsCount) => {
if (this.length !== rowsCount * colsCount) return [];
let reuslt = [];
for (let i = 0; i < rowsCount; i++) {
result.push([]);
}
// 正向还是反向
let seq = true;
let start = 0;
for (let i = 0; i < this.length; i++) {
result[start].push(this[i]);
// 如果是正向
if (seq) {
// 如果走完同系列同索引的添加
if (start === rowsCount - 1) {
seq = false;
} else {
start++;
}
}
// 反向
else {
// 如果走完同系列同索引的添加
if (start === 0) {
seq = true;
} else {
start--;
}
}
}
return result;
};Array.prototype.snail = (rowsCount, colsCount) => {
if (this.length !== rowsCount * colsCount) return [];
let reuslt = [];
for (let i = 0; i < rowsCount; i++) {
result.push([]);
}
// 正向还是反向
let seq = true;
let start = 0;
for (let i = 0; i < this.length; i++) {
result[start].push(this[i]);
// 如果是正向
if (seq) {
// 如果走完同系列同索引的添加
if (start === rowsCount - 1) {
seq = false;
} else {
start++;
}
}
// 反向
else {
// 如果走完同系列同索引的添加
if (start === 0) {
seq = true;
} else {
start--;
}
}
}
return result;
};复合函数
请你编写一个函数,它接收一个函数数组 [f1, f2, f3,…, fn] ,并返回一个新的函数 fn ,它是函数数组的 复合函数 。
[f(x), g(x), h(x)] 的 复合函数 为 fn(x) = f(g(h(x))) 。
一个空函数列表的 复合函数 是 恒等函数 f(x) = x 。
你可以假设数组中的每个函数接受一个整型参数作为输入,并返回一个整型作为输出。
示例 1:
输入:functions = [x => x + 1, x => x * x, x => 2 * x], x = 4
输出:65
解释:
从右向左计算......
Starting with x = 4.
2 * (4) = 8
(8) * (8) = 64
(64) + 1 = 65
示例 2:
输出:functions = [x => 10 * x, x => 10 * x, x => 10 * x], x = 1
输入:1000
解释:
从右向左计算......
10 * (1) = 10
10 * (10) = 100
10 * (100) = 1000
示例 3:
输入:functions = [], x = 42
输出:42
解释:
空函数列表的复合函数就是恒等函数示例 1:
输入:functions = [x => x + 1, x => x * x, x => 2 * x], x = 4
输出:65
解释:
从右向左计算......
Starting with x = 4.
2 * (4) = 8
(8) * (8) = 64
(64) + 1 = 65
示例 2:
输出:functions = [x => 10 * x, x => 10 * x, x => 10 * x], x = 1
输入:1000
解释:
从右向左计算......
10 * (1) = 10
10 * (10) = 100
10 * (100) = 1000
示例 3:
输入:functions = [], x = 42
输出:42
解释:
空函数列表的复合函数就是恒等函数解法
本质上就是一个倒叙数组,然后循环数组内的 fn 不断的对传进来的值进行更改,然后 return 出来。
const compose = (functions) => {
return function (x) {
functions.reverse().forEach((fn, index) => {
x = fn(x);
});
return x;
};
};const compose = (functions) => {
return function (x) {
functions.reverse().forEach((fn, index) => {
x = fn(x);
});
return x;
};
};嵌套数组生成器
现给定一个整数的 多维数组 ,请你返回一个生成器对象,按照 中序遍历 的顺序逐个生成整数。 多维数组 是一个递归数据结构,包含整数和其他 多维数组。 中序遍历 是从左到右遍历每个数组,在遇到任何整数时生成它,遇到任何数组时递归应用 中序遍历 。
示例 1:
输入:arr = [[[6]],[1,3],[]]
输出:[6,1,3]
解释:
const generator = inorderTraversal(arr);
generator.next().value; // 6
generator.next().value; // 1
generator.next().value; // 3
generator.next().done; // true
示例 2:
输入:arr = []
输出:[]
解释:输入的多维数组没有任何参数,所以生成器不需要生成任何值。示例 1:
输入:arr = [[[6]],[1,3],[]]
输出:[6,1,3]
解释:
const generator = inorderTraversal(arr);
generator.next().value; // 6
generator.next().value; // 1
generator.next().value; // 3
generator.next().done; // true
示例 2:
输入:arr = []
输出:[]
解释:输入的多维数组没有任何参数,所以生成器不需要生成任何值。解法
本质上是平铺数组,然后利用yield迭代器对数据进行抛出,那么解法就非常简单了。
var inorderTraversal = function* (arr) {
let result = [];
const isOkArray = (data) => {
return Array.isArray(data) && data.length;
};
const fn = (data) => {
if (isOkArray(data)) {
data.forEach((el) => {
if (isOkArray(el)) fn(el);
else if (!isOkArray(el) && el.length !== 0) result.push(el);
});
}
};
fn(arr);
for (let i of result) {
yield i;
}
};var inorderTraversal = function* (arr) {
let result = [];
const isOkArray = (data) => {
return Array.isArray(data) && data.length;
};
const fn = (data) => {
if (isOkArray(data)) {
data.forEach((el) => {
if (isOkArray(el)) fn(el);
else if (!isOkArray(el) && el.length !== 0) result.push(el);
});
}
};
fn(arr);
for (let i of result) {
yield i;
}
};